coBib becomes fuzzy!
A long-desired feature has just landed in coBib v5.1.0: the ability to fuzzy-find entries in the database! In this post I will briefly showcase this functionality and how it can make your life easier.
TL;DR
For the list and search commands you now have three new command-line
arguments:
1
2
3
cobib search --decode-latex "naïve" # will still find `na{\"\i}ve`
cobib search --decode-unicode "naive" # will still find `naïve`
cobib search --fuzziness 1 "naive" # also finds `naïve`
For the list command, these argument affect the filter mechanism.
You can set your own default values via the respective settings in your
configuration file.
What is fuzzy finding?
Fuzzy finding refers to approximate string matching1 which allows you to relate two strings to each other if they are approximately equal. What exactly this approximation entails can differ; but in general there are three primitive kinds of errors:
- insertions:
cot -> cost - deletions:
coat -> cot - substitutions:
coat -> cost
The more errors you allow, the more approximate (or “fuzzy”) your comparison becomes.
How can you use this in coBib?
coBib v5.1.0 has added support for approximate string comparisons for two use cases:
- when using filters to limit the output of the
listcommand - when searching your database with the
searchcommand
In both of these cases, coBib relies on the functionality provided by the
regex2 package. This is a new optional dependency of coBib, so be sure to
install it if you want to use this functionality.
Since the regex package is a drop-in replacement for Python’s builtin
re3 module, and coBib already supported standard regex patterns for both of
these use cases, the extension to support fuzzy matching was almost straight
forward.
In the following, we will explore the new ways for fuzzy finding entries in your database, using the following entry as our example:
1
2
3
4
5
6
7
8
9
@unpublished{Battaglia2024,
archivePrefix = {arXiv},
arxivid = {2404.18737v1},
author = {Battaglia, Stefano and Rossmannek, Max and Rybkin, Vladimir V. and Tavernelli, Ivano and Hutter, J{\"u}rg},
eprint = {http://arxiv.org/abs/2404.18737v1},
primaryClass = {physics.chem-ph},
title = {A general framework for active space embedding methods: applications in quantum computing},
year = {2024}
}
Using regex patterns directly
You have full control over the regex patterns that are used for filter matching
and/or searching. As such, you can use all of the additional features provided
by the regex package.
In the following, we will review how to write custom patterns to allow for the different kinds of errors listed above.
Insertion errors
We can allow a number of characters to be inserted into our query string by
writing a regex pattern of the form: (Rossmanek){i<2}.
This will match all occurrences of Rossmanek with up to one additional
arbitrary characters inserted into it, e.g. Rossmannek.
Let’s try it out:
1
cobib list ++author "(Rossmanek){i<2}"
And indeed, the query was able to find our entry above:
1
2
3
4
5
6
7
8
┏━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ label ┃ title ┃ author ┃
┡━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ Battaglia2024 │ A general framework for │ Battaglia, Stefano and │
│ │ active space embedding │ Rossmannek, Max and Rybkin, │
│ │ methods: applications in │ Vladimir V. and Tavernelli, │
│ │ quantum computing │ Ivano and Hutter, J{\"u}rg │
└────────────────┴───────────────────────────────┴───────────────────────────────┘
Deletion errors
Deletions work just like insertions above, but using d instead of i:
1
cobib list ++author "(Rossmanneck){d<2}"
(This matches the entry just like in the previous example.)
Substitution errors
The third kind of error are substitutions which are equivalent to the insertion
and removal of a character at the same location. You can specify their number
using s:
1
cobib list ++author "(Maz){s<2}"
(This matches the entry just like in the previous example.)
Allowing multiple errors types
You can even combine these errors types. Below we allow an insertion and deletion to occur:
1
cobib list ++author "(Rossmaneck){i<2,d<2}"
(And again, this matches the entry just like in the previous example.)
Generic errors
Finally, you can allow any type of error (i.e. without specifying its type)
using e:
1
cobib list ++author "(Rossmaneck){e<3}"
The --fuzziness command-line option (or -z for short)
Since writing these regex patterns can be a bit cumbersome, the --fuzziness
argument makes enabling fuzzy finding a lot easier. It is best explained using
an example:
1
cobib list --fuzziness 3 ++author "Rossmaneck"
This command is equivalent to the previous example. Here is what happens under the hood:
- the provided string gets wrapped in parentheses:
Rossmaneck -> (Rossmaneck) - the provided value of fuzziness gets used as the allowed number of
arbitrary errors:
{e<3} - the two parts get concatenated to form the final query:
(Rossmaneck){e<3}
You can also use -z as a short-hand instead of typing out --fuzziness every
time.
Setting a default --fuzziness value
If you want to enable approximate string matching by default, you can do so by including the following in your configuration file:
1
2
3
from cobib.config import config
config.commands.list_.fuzziness = 3
And although we only used the list command in our examples above, the search
command provides the same features:
1
config.commands.search.fuzziness = 3
Finally, you can always overwrite this default value with the command-line
option. For example, --fuzziness 0 will disable fuzzy finding.
Dealing with LaTeX sequences
Accounting for typos by fuzzy matching is nice, but it would require a large
threshold of --fuzziness to be able to deal with LaTeX sequences such as the
one found in our example: J{\"u}rg.
Instead, coBib v5.1.0 added another way to deal with LaTeX sequences: the
--decode-latex command-line option. Setting this will convert LaTeX code to
plain text using pylatexenc’s4 encoder.
Note, that this only works approximately and only for sequences which can actually be rendered in plain text using Unicode characters.
This allows you to do the following:
1
cobib list --decode-latex ++author "Jürg"
which will again match our entry Battaglia2024 shown above.
The same command-line setting is available for the search command (where it
even comes with the -l short-hand).
Configuring the default of --decode-latex
Just like for the --fuzziness setting, you can also configure the default
value for the --decode-latex option:
1
2
config.commands.list_.decode_latex = True
config.commands.search.decode_latex = True
If you enable this setting, you can still overwrite it from the command-line
using the --no-decode-latex argument (or -D for the search command).
Dealing with Unicode characters
We can take the concept of special character decoding one step further by also
leveraging text-unidecode5 to convert Unicode characters into their
approximate ASCII version.
Pairing this with LaTeX decoding allows us to match our entry with an even simpler query:
1
cobib list --decode-latex --decode-unicode ++author "Jurg"
And, once again, you can do the same within the search command (where it also
comes with the -u short-hand).
Configuring the default of --decode-unicode
Of course, you can also configure the defaults for these options:
1
2
config.commands.list_.decode_unicode = True
config.commands.search.decode_unicode = True
And you can overwrite the enabled settings using --no-decode-unicode (or -U
for the search command).
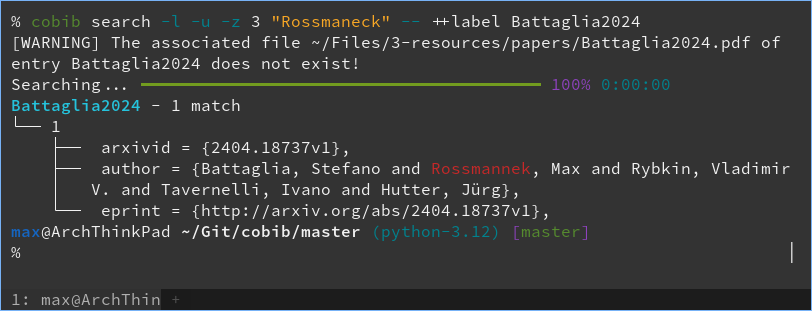
Fuzzy search highlights
As a final little example, here you can see that even the highlighting of search results works properly for fuzzy matches: